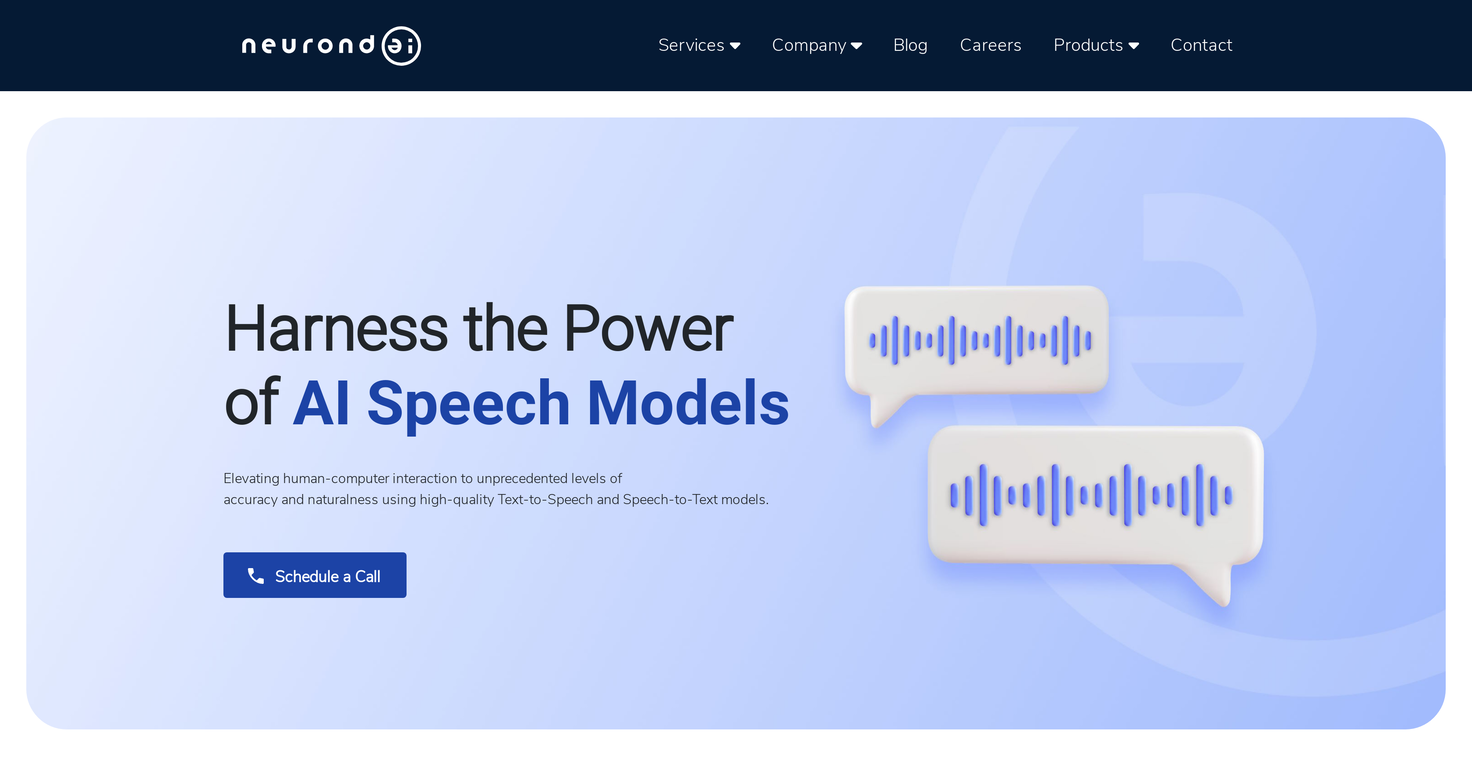
What is Neurond Voice Model Implementation?
Neurond Voice Model Implementation is a service by Neurond AI, designed to enhance human-computer interaction through high-quality Text-to-Speech and Speech-to-Text models. This service is designed and maintained by a team experienced in voice transcription and text conversion systems, with an emphasis on precision and accuracy. It also provides customized solutions utilizing features like WHISPER, FAST WHISPER, INSTANT-FAST-WHISPER, and BARK.
What does Neurond Voice Model Implementation help with?
Neurond Voice Model Implementation supports accurate and swift text-to-speech and speech-to-text conversions. It helps enhance human-computer interaction and communication accessibility, making possible hands-free alternatives to traditional typing. It can be used in several applications, such as voice assistants, transcription services, dictation software, GPS systems, public announcements, and telecommunications.
What is the role of the FASTSPEECH 2 model in Neurond Voice Model Implementation?
FASTSPEECH 2 model is employed in Neurond Voice Model Implementation to facilitate quicker, smoother and more human-like speech synthesis.
What are the features of Neurond Voice Model Implementation?
Neurond Voice Model Implementation features WHISPER for accurate transcription of nuances, accents, and terminologies across multiple domains. FAST WHISPER offers rapid conversion fitting time-sensitive applications. INSTANT-FAST-WHISPER facilitates real-time responses to lengthier audio or video inputs. BARK synthesis human-like speech from vast text volumes. It also provides SEAMLESS STREAMING to ensure continuous speech flow and incorporates the FASTSPEECH 2 model for quicker, human-like speech synthesis.
What does the WHISPER feature do in Neurond Voice Model Implementation?
In Neurond Voice Model Implementation, the WHISPER feature is designed to understand and accurately transcribe nuances, accents, and terminologies across multiple domains.
How does FAST WHISPER work in Neurond Voice Model Implementation?
In Neurond Voice Model Implementation, the FAST WHISPER feature provides rapid conversion, which makes it ideal for time-sensitive applications without sacrificing the quality of outputs.
What applications does Neurond Voice Model Implementation cater to?
Neurond Voice Model Implementation caters to applications like GPS systems, public announcements, telecommunications, voice assistants, transcription services, and dictation software.
What is the role of Neurond Voice Model Implementation in dictation software?
In dictation software, Neurond Voice Model Implementation plays a significant role in maximizing productivity and convenience. It offers a hands-free alternative to traditional typing, enabling users to express their thoughts verbally instead of via typed text.
Can Neurond Voice Model Implementation be used with GPS systems?
Yes, Neurond Voice Model Implementation can be employed with GPS systems. It facilitates safer driving by providing spoken directions, eliminating the need for users to take their eyes off the road to glance at the device.
How does Neurond Voice Model Implementation handle public announcements?
In terms of public announcements, Neurond Voice Model Implementation can be used to improve public information broadcasting through verbal delivery—ideal for environments such as airports or railway stations.
Can Neurond Voice Model Implementation work in real-time?
Yes, Neurond Voice Model Implementation supports real-time responses, especially with the INSTANT-FAST-WHISPER feature. It is capable of providing instant responses to lengthy audio or video within minutes.
Does Neurond Voice Model Implementation offer customization options?
Yes, Neurond Voice Model Implementation offers customization options, allowing the creation of distinctive solutions that fit the requirements and complement the vision of the user's business.
What is the level of scalability offered by Neurond Voice Model Implementation?
Neurond Voice Model Implementation offers high scalability. Its solutions scale along with an exponential growth of the user base, consistently maintaining performance and reliability.
How can Neurond Voice Model Implementation be integrated into web applications?
Neurond Voice Model Implementation can be seamlessly integrated into web applications, ensuring the provision of important features like text-to-speech and speech-to-text within these platforms.
How is SEAMLESS STREAMING employed in Neurond Voice Model Implementation?
The feature of SEAMLESS STREAMING in Neurond Voice Model Implementation provides a constant flow of speech without interruption or delay, hence enhancing user satisfaction.
Is Neurond Voice Model Implementation ideal for mobile platforms?
Yes, Neurond Voice Model Implementation is ideal for mobile platforms. It is designed for seamless integration into mobile systems, allowing users to harness its services efficiently regardless of the device they are using.
Can Neurond Voice Model Implementation be integrated through APIs?
Yes, Neurond Voice Model Implementation can be integrated through APIs, offering simple and convenient access to its features for developers.
How does BARK feature work in Neurond Voice Model Implementation?
The BARK feature in Neurond Voice Model Implementation is designed to produce human-like speech from vast amounts of text, upholding a remarkable level of naturalness in the synthesized speech.
What makes Neurond Voice Model Implementation's voice synthesis human-like?
The human-like voice synthesis in Neurond Voice Model Implementation is made possible by features like the FASTSPEECH 2 model, which synthesizes speech faster with smoother and more human-like output, and the BARK feature, which produces human-like speech from vast amounts of text with remarkable naturalness.
How can Neurond Voice Model Implementation enhance transcription services?
Neurond Voice Model Implementation enhances transcription services through its high-quality voice transcription and text conversion systems. By providing tailored solutions with exceptional accuracy, it enables enhanced communication accessibility, catering to real-time captions for live events, meetings, or broadcasts.
 Listen to articles, PDFs, emails, etc. in your podcast player or browser.8742
Listen to articles, PDFs, emails, etc. in your podcast player or browser.8742 4056
4056 3621
3621 247
247 2388
2388 208
208 1145
1145 100
100 69
69 68
68 65
65 58
58 56
56 55
55 51
51 503
503 49
49 45
45 454
454 422
422 40
40 361
361 35
35 29
29 28
28 25
25 22
22 21
21 194
194 19
19 18
18 181
181 18
18 17
17 17
17 16
16 16
16 151
151 14
14 131
131 Create voice recordings for Youtube Videos, Facebook Ads, Instagram Posts or Create Audio versions of content in just a few steps!13
Create voice recordings for Youtube Videos, Facebook Ads, Instagram Posts or Create Audio versions of content in just a few steps!13 131
131 13
13 12
12 125K
125K 11
11 11
11 11
11 11
11 Transform and Convert any Text content to Voice Speech MP3 with AI in just a few seconds!10
Transform and Convert any Text content to Voice Speech MP3 with AI in just a few seconds!10 10
10 9
9 9
9 9
9 8108
8108 8
8 8
8 7186
7186 71
71 7
7 71
71 5
5 5
5 5
5 4
4 4
4 4
4 3
3 3
3 3
3 3
3 3
3 3
3 1
1 1
1 11
11 1
1








